](https://med-karim-ben-boubaker.github.io/covers/plan-and-act-cover.png)
TL; DR
Large Language Models (LLMs) are great at simple tasks, but they fall short when it comes to complex, goal-directed behaviour, especially in unpredictable environments like the web. PLAN-AND-ACT (Erdogan et al. (2025)) is a system that separates high-level planning (what to do and why) from low-level execution (how to do it), and trains both using synthetic data pipelines. The key innovation? Instead of planning forward, they reverse-engineer plans from successful executions, making them grounded and effective. The results show this strategy leads to state-of-the-art performance in real-world web navigation.
Large Language Models (LLMs) are excellent at simple and straightforward tasks. Ask them to summarize an article or write a simple email, and they do it easily. But when faced with complex, multi-step challenges, especially in dynamic environments like the web, things become too difficult.
The main problem is that LLMs are not trained enough to do long-term planning in environments where the situation changes constantly. Their static nature makes them struggle to adapt to changes. And this is fundamentally because of the scarcity of high-quality planning data around the internet.
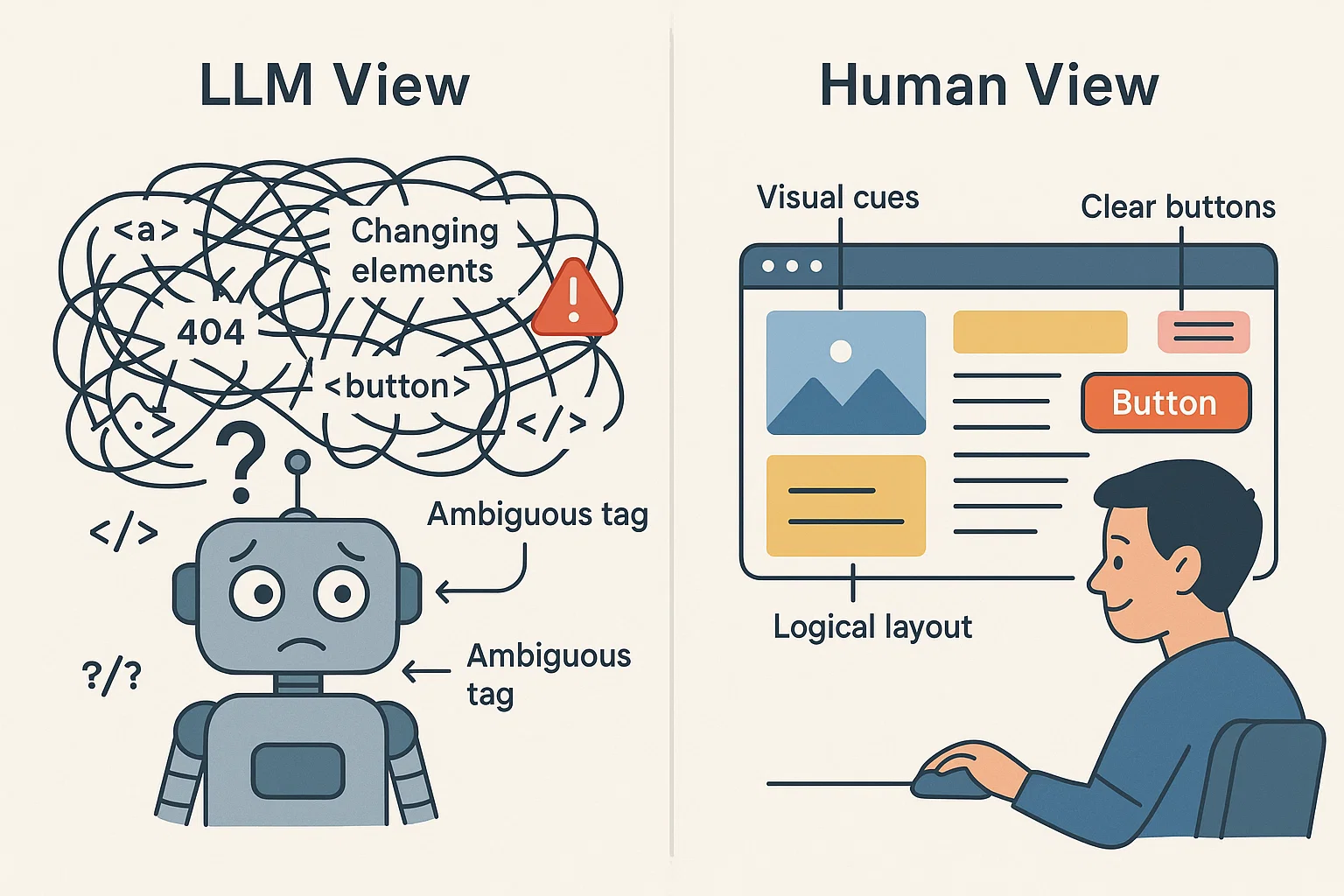
Figure 1: An illustration that shows the difference between LLMs and humans in the way ther perceive the web.
Imagine an agent trying to complete the complex task of booking or managing a project through an unfamiliar webpage. While it can be intuitive for us, since webpages are designed around the human visual system, agents only see text. Pure HTML comes with no visual context. A simple wrong tag labelling can make the agent do something completely wrong.
Separating Roles, PLAN then ACT
What if we could design an LLM agent with fundamentally two different parts? One focuses on the high-level tasks, and the other is responsible for the precise actions.
This is the main idea behind PLAN-AND-ACT, an architecture that aims to make LLMs more adaptive and goal-oriented by separating thinking and doing.
So, how does this system achieve this? It simply divides the agent’s brain into two clear, connected components:
The Planner acts as a high-level sub-task generator, much like a project manager assigning tasks to a team. When a user provides a broad goal, such as “find the cheapest direct flight from Tunisia to Italy,” the Planner breaks it down into clear, manageable steps. Its primary role is to determine the “what” and the “why” of these actions (Section 3.1).
For example:
- Navigate to a flight search page
- Input the origin and destination
- Set the dates
- Filter for direct flights and find the price
Its job is to know what to do and why it’s needed.
Next, there’s the Executor. This LLM acts as a tool invoker and action-taker. It receives the high-level steps from the Planner and translates them into specific, immediate actions for the environment (Section 3.2). For example, If the planner says, “Navigate to the flight search page,” the executor knows what to do next:
- Click on the “Flights” tab
- Look for a prominent “Book a Flight” button
- Type “flights” into the search bar
The executor focuses on the how of doing things.
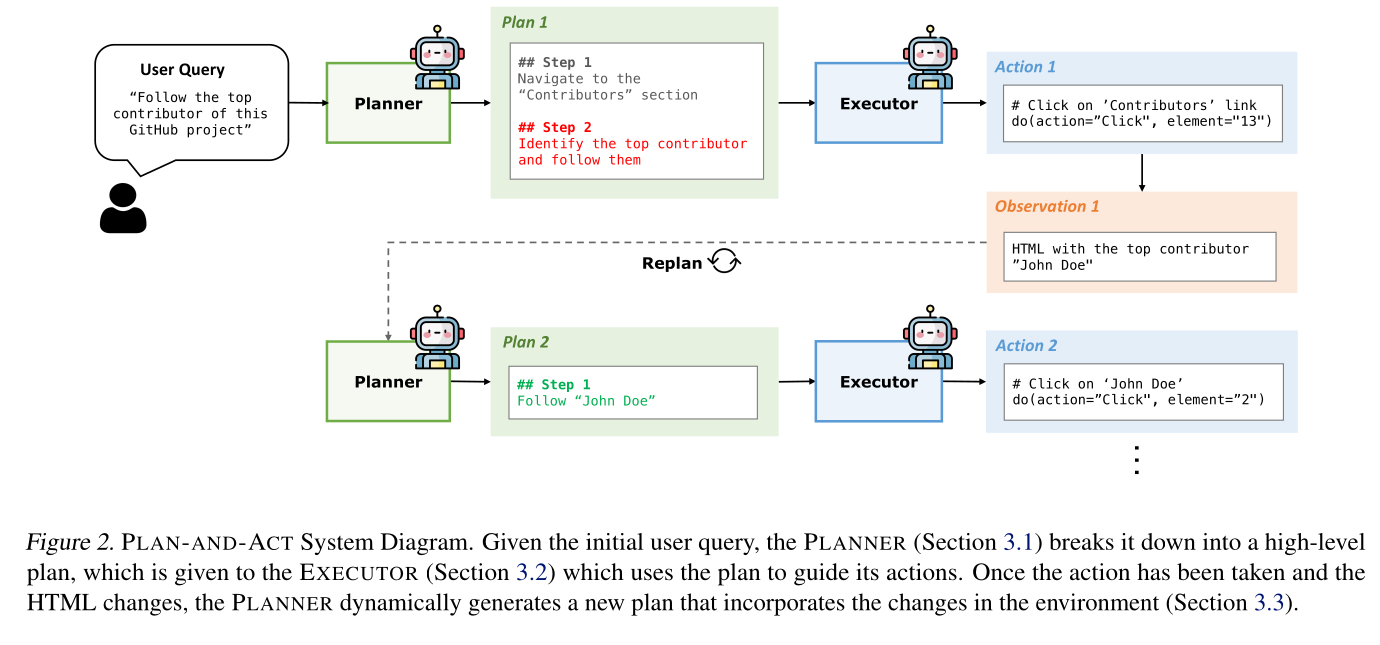
Figure 2: PLAN-AND-ACT System Diagram Erdogan et al. (2025)
Why does this separation work?
Trying to force one model to plan and act simultaneously creates too much noise. The paper assumes this dual responsibility overloads the context window and confuses the model. Separating the responsibilities simplifies the task for both components.
Synthetic Data Generation
As previously noted, Large Language Models (LLMs) inherently lack robust planning capabilities. This assertion is supported by Yann LeCun, who describes LLMs as “mere token generators,” underscoring their deficiency in essential planning functions. Furthermore, LLMs are typically not well-trained or fine-tuned on high-quality planning data. These limitations present a significant challenge for developing an effective planning node.
So, the paper introduces its true innovation: synthetic data generation. They designed a scalable synthetic data generation pipeline, which might become a foundational method in agentic AI systems.
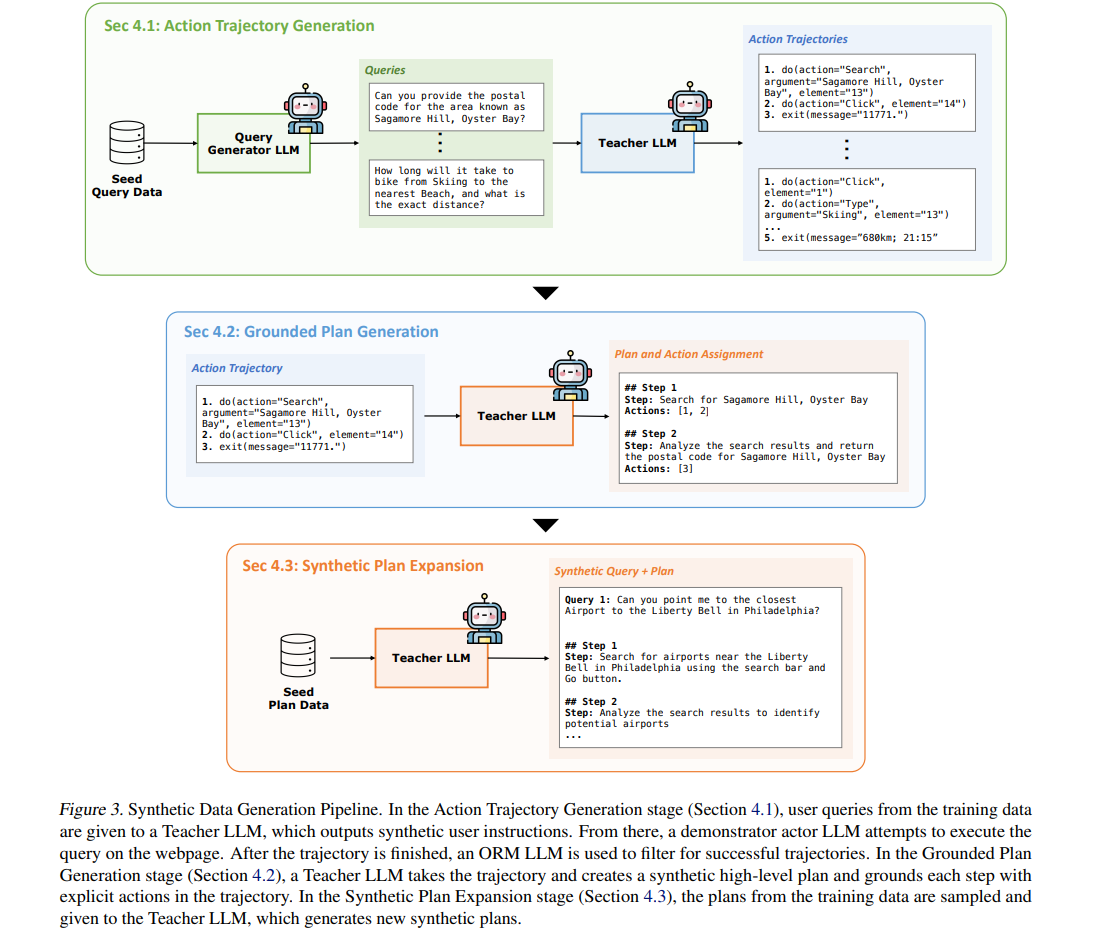
Figure 3: Synthetic Data Generation Pipeline. Erdogan et al. (2025)
Teaching the Executor: Generating Action Trajectories
The Executor needs to learn how to interact with websites. This means gathering lots of (query, action sequence) examples (Section 4.1).
- Teacher LLM Generates Diverse Queries: They start with a small set of hand-written queries. Then, GPT-4o creates thousands of variations like:
“Find the cheapest direct flight from Tunisia to Italy for August 20th, departing after 3 PM.”
- Demonstrator Agent Executes Tasks: These queries are passed to a capable web agent (WebRL-Llama-3.1-70B) in a simulated environment like WebArena-Lite. While the agent performs actions, each move is recorded. Only the successful trajectories are kept.
- eward Model Filters the Good Trajectories: After the agent finishes, an Outcome-Supervised Reward Model (ORM) like ORM-Llama-3.1-8B checks if the task was successful using predefined rules (Section 4.1, Section 5.1). Only those passing the filter become training data for the Executor.

Figure 4: Synthetic Data Generation Pipeline - Action Trajectory Generation. Erdogan et al. (2025)
Grounding the Planner: Reverse Engineering
Traditionally, asking an LLM to “Generate a plan for ‘book a flight’” yields a generic, logical-sounding sequence like “Navigate to the flight search page, input origin and destination, select dates.”
The problem is, LLMs can’t “see” a website. They don’t know if a “flight search page” is a direct link or what a date picker looks like. This gap makes these logical sounding but “ungrounded plans” impossible to carry out in the real world. Such broad plans would simply confuse an executor.
PLAN-AND-ACT flips this around. Instead of “forward planning” (creating a plan first, which often leads to wrong assumptions), it reverse-engineers the plan from what actually worked (Section 4.2). This clever twist is key to its innovative approach.
The Teacher LLM is important for making these practical plans.
- Gets Information: The Teacher LLM receives two main things: the user’s original request (what they wanted to achieve) and the successful steps the Executor took to complete the task.
- Figures Out a General Plan: Using its natural ability to summarize and find common themes, the Teacher LLM examines these successful steps. It identifies smaller actions that naturally group together to achieve a clear mini goal.
- Combines Actions into Plan Steps: For instance, a series of actions like “clicking a box,” “typing words,” and “pressing enter” might be combined into a single, higher-level plan step, like “Type in where you’re flying from.”
- Connects Plans to Real Actions: Most importantly, the Teacher LLM also highlights which specific actions from the original successful list (e.g., actions 1, 2, and 3) correspond to each new plan step. This connection is vital. It guarantees that the plans aren’t just theoretical but are firmly based on actual, successful actions, making them useful and ready for the Executor to follow.
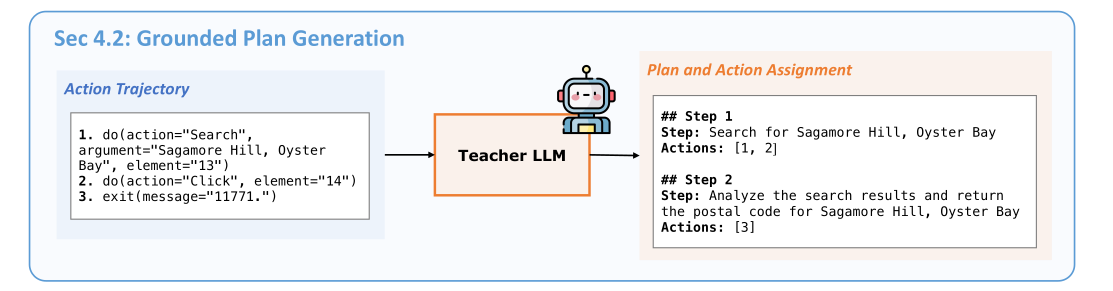
Figure 5: Synthetic Data Generation Pipeline - Grounded Plan Generation. Erdogan et al. (2025)
Generating More Planner Data: Alpaca-Style Expansion
Now we have a new issue. One long, successful action trajectory doesn’t necessarily generate one high-level plan for the planner. Which means that we will end up with more “action” training data than “plan” training data. So, there’s a data imbalance here (Section 4.3).
Also, generating the full action trajectories is a very slow process because of the simulation and recording process. This is why we also need a synthetic data generation method for the Planner’s data.
Here, they also use Teacher LLM, similar to a method known as “Alpaca-style instruction generation.” Which is the basic idea of giving an LLM a few good starting examples and making it create many more new training examples, following the same structure and logic. The prompt for this looks like this (Appendix A.6):
This method is very effective. The paper notes that they have generated 10,000 additional query-plan pairs in under an hour using GPT-4o, which is incomparable to the days or weeks it would take to collect 10,000 full action trajectories through simulation. The approach sped up the process of getting enough high-quality planning data.
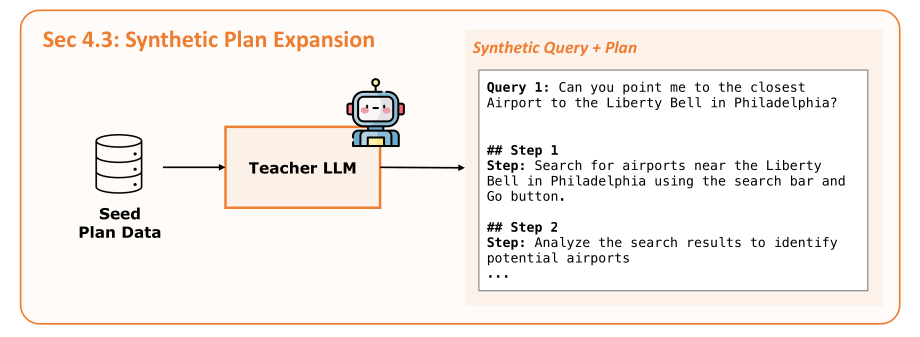
Figure 5: Synthetic Data Generation Pipeline - Synthetic Plan Expansion. Erdogan et al. (2025)
Dynamic Replanning
Even a good plan needs to adapt. Sticking to one plan isn’t always wise, especially when new situations pop up. This is where the concept of dynamic replanning becomes crucial (Section 3.3).
In this system, the Planner actually updates its plan after every single action the Executor takes (Section 3.3). This continuous adjustment is incredibly important in ever-changing web environments. For instance, if the Executor tries to click a button that isn’t there, the Planner immediately revises its strategy, either by attempting a different approach or choosing an alternative action (Section 3.3, Appendix A.2).
Both the Planner and Executor also use Chain-of-Thought (CoT) Reasoning (Section 3.4). This means they’re prompted to generate intermediate reasoning steps before delivering their final plan or action. This adds a layer of interpretability, as the Planner will explain its chosen steps, and the Executor will do the same for its actions (Section 3.4).
Testing the System
We’ve explored the architecture and the clever synthetic data pipeline. But the most important question remains: does it actually deliver? Do all these changes to how it’s built and how data is made truly lead to better performance? What did the results reveal, and what can we learn from them?
The researchers primarily tested PLAN-AND-ACT on the WebArena-Lite benchmark (Section 5.1). This benchmark features 165 web navigation tasks spanning various web environments, including sites like Reddit and GitLab (Section 5.1).
The evaluation was straightforward: did the agent successfully complete the task, yes or no? For this particular benchmark, they used Llama-3.3-70B-Instruct models for both the Planner and the Executor.
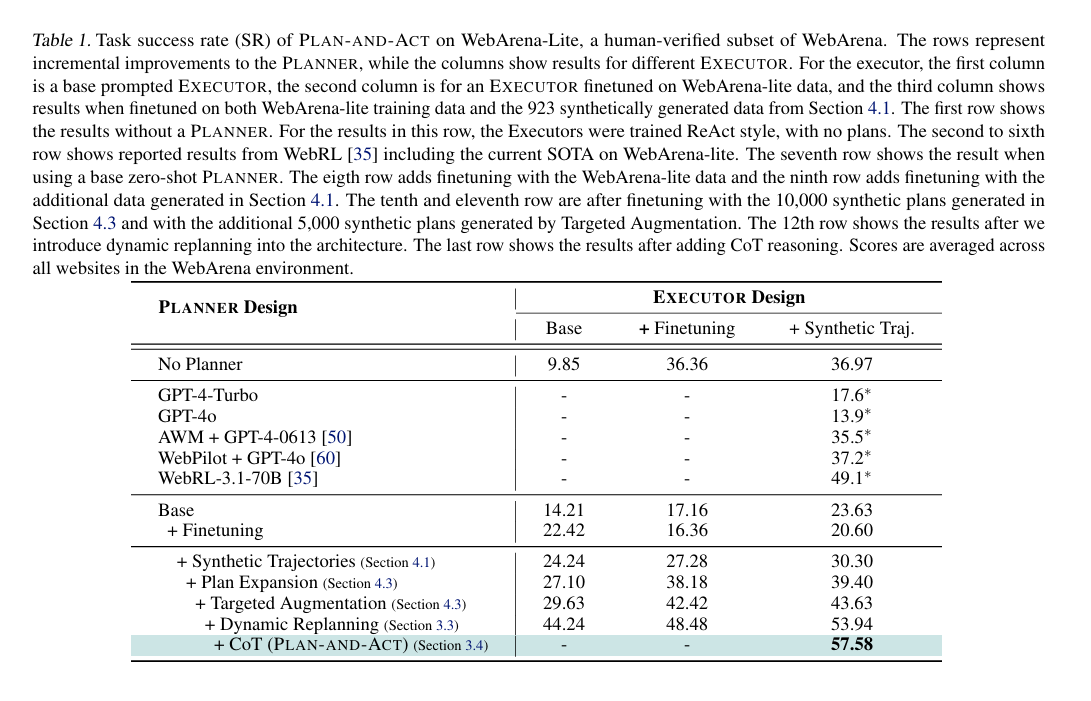
Table 1: The table shows the task success rate (SR) of PLAN-AND-ACT on WebArena-Lite (Table 1). The approach achieved a state-of-the-art result of 57.58%.
The most impressive results is the part where their QWQ-32B based agent achieved an 81.36% success rate, setting a new leading result for text-only agents on this real-world benchmark (Section 5.5, Table 4).

Table 2: This table shows that the innovative synthetic data generation pipelines and agentic architectures can make Smaller LLMs outperform better than SOTA LLMs (Table 1, Table 4).
Conclusion
In summary, the combination of PLAN-AND-ACT’s separate planning and execution, dynamic replanning, a comprehensive synthetic data pipeline for training, and Chain-of-Thought reasoning delivered top-tier results in both controlled settings and the open web. This points to a powerful new design pattern and framework for building more capable AI agents.
So, what are the key takeaways for engineers aiming to build more advanced systems?
- Explicit Planning Works Well: Separating planning from actual execution greatly simplifies tasks for LLMs and significantly boosts performance. It gives our models a more organized way to “think” before they “act” (Section 6).
- Synthetic Data is Very Important: It’s not just helpful; it’s crucial for overcoming the shortage of real-world data, especially for complex planning tasks. Every step of their pipeline—from creating action paths to forming grounded plans, expanding them, and adding specific details—provides significant, measurable benefits. It’s a prime example of using LLMs to create the data they need to learn (Section 5.2, Section 6).
- Adaptability is Necessary: Dynamic replanning is essential for real-world robustness. It enables an agent to correct its course, remain consistent, and succeed in ever-changing web environments. Fixed plans simply aren’t enough (Section 5.3, Section 6).
- Reasoning Quality Matters: Incorporating Chain-of-Thought reasoning further enhances the internal decision-making process. It helps guide better choices, providing that final, crucial improvement in accuracy (Section 5.3.2, Section 6).
This research goes beyond just making slightly better web agents. It offers a strong framework for tackling complex, multi-step problems in AI more broadly. As LLMs continue to advance, architectures like PLAN-AND-ACT demonstrate how to harness their power not just for generating language but for intelligent, independent actions in the real world. It’s a thrilling time to be involved in this field.